Details
-
Type:
New Feature
-
Status: Open
-
Priority:
 Minor
Minor
-
Resolution: Unresolved
-
Affects Version/s: None
-
Fix Version/s: Sustaining
-
Component/s: Cloud Spider
-
Labels:None
Description
From SEO Team:
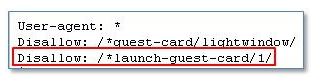
We’ve noticed some blocked URLs showing up in ADRs, even when robots.txt is honored. This appears to be due to the use of a wildcard ![]() . Example:
. Example:
Last week, AvalonCommunities added Disallow: /*launch-guest-card/1/ to their robots.txt file, in order to block URLs such as http://www.avaloncommunities.com/maryland/gaithersburg-apartments/avalon-rothbury/launch-guest-card/1/.
(Attachment 1)
Crawling the site afterward, these URLs continue to appear in the ADR:
(Attachment 2)
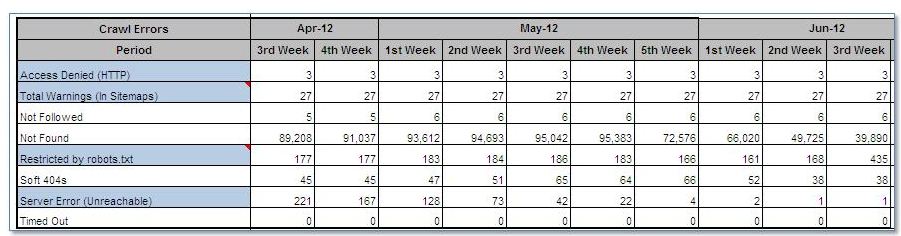
Google is honoring the disallow. Looking at our monitoring report, the GWT’s number of URLs restricted by robots.txt increased from 168 to 435 in the week following the robots.txt update.
(Attachment 3)
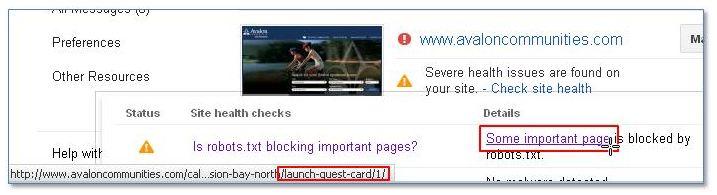
And there was a warning related to one of the URLs specifically being blocked by robots.txt:
(Attachment 4)
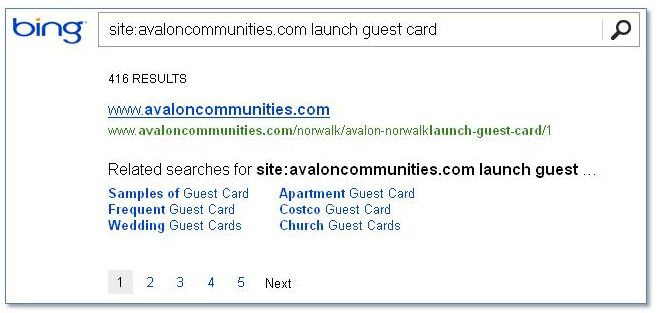
Bing is showing only reference URLs for these pages now:
(Attachment 5)
Not sure if this has come up before, but would it be possible for our spider to support the wildcard character when robots.txt is honored?
----------
Avalon Communities is the only client I work with who is currently using wildcards in their robots.txt. The first instance was added to the file in March, and all ADRs generated since then have included blocked URLs.
Pro: Adding this feature would mean that the ADRs would present a more accurate picture of what search engines are seeing when they crawl a site. Currently the ADR may be flagging issues, such as duplicate content and other on-page factors, that are not actually being seen by search engine spiders, and are therefore generally irrelevant. To gather only the relevant data, for presenting to clients or for our own monitoring/auditing purposes, manually checking the robots.txt file and filtering the data accordingly is necessary.
Con: I don’t see any cons – the option to not honor robots.txt is available if there is a need to crawl these pages.